


Por: Marcos Leone e Paulo Mayon*
No nosso artigo anterior discutimos em linhas gerais o que são ferramentas de Inteligência Artificial (IA), e ao mesmo tempo exemplificamos as situações em que não deveríamos aplicá-las (em problemas com solução fechada existente).
Hoje vamos avançar mais um passo, discutindo como e quando aplicar ferramentas de IA. Para ilustrar, apresentamos abaixo um caso hipotético de uma análise de crédito.
Imaginemos que um dia você tivesse que tratar o seguinte problema: aprovar ou recusar a abertura de um relacionamento comercial entre sua empresa e uma determinada contraparte.
Esta aprovação ou reprovação seria feita mediante a análise de informações disponíveis sobre tal contraparte. Assim, poderíamos resumir o problema da seguinte maneira:
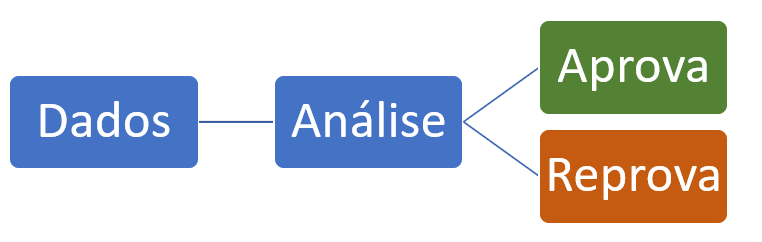

Figura 1: Fluxograma básico de um processo de análise de crédito
Uma análise de crédito convencional analisará e criticará os dados obtidos. Essa crítica os transformará em informações, que após o devido escrutínio (atribuição de pesos ou métricas de comparação) deverão gerar notas para diferentes quesitos. Estas notas podem, eventualmente, até serem combinadas, o que normalmente desemboca em um score, ou nota final. Essa nota ao final, é o que classifica (podendo inclusive quantificar) o risco da contraparte analisada.
Entretanto, após esta análise começam a surgir as primeiras perguntas:
-
Qual score você poderia assumir como suficientemente bom para aprovar uma negociação? - As informações disponíveis são suficientes?
- O meu modelo reflete a cultura de risco da minha empresa?
Em geral estas perguntas não são fáceis de serem respondidas e elas costumam “perseguir” todos aqueles que trabalham com análise de risco de crédito. Contudo, imagine uma situação hipotética na qual você possui um enorme conjunto histórico de dados sobre todas estas contrapartes e, além disto, também armazenou todo o histórico de negociações delas com a sua empresa e com outras companhias que possuem a cultura de risco similar.
Com toda essa base histórica organizada, imagine que você também conheça a existência de qualquer situação de default ou não, que tenha ocorrido em determinada janela temporal, dentro desse universo de empresas.
Agora, considere que adicionalmente a este enorme conjunto de dados, você também tenha estudado todas as informações disponíveis e mesmo assim, com tantos inputs, não tenha conseguido achar um caminho (ou modelagem) que possa gerar resultados precisos para sugerir a aprovação ou reprovação dessa transação.
É justamente quando você se encontra neste cenário (um conjunto enorme de dados e até informações tratadas que se deparam com a impossibilidade de conceber um modelo analítico fechado), que a utilização de uma ferramenta de IA começa a se desenhar como plausível.
Imagine por exemplo, que você pesquisou bastante (não abordaremos neste artigo como escolher a melhor ferramenta de IA, pois, este processo é muito complexo e depende de muitas variáveis) e identificou que a utilização de “Redes Neurais Artificiais” (RNAs – uma das ferramentas de Inteligência Artificial mais conhecidas) seria uma boa opção.
Como vimos na Figura 1 do artigo anterior, uma ferramenta de IA segue o fluxo básico do tipo “percepção-avaliação-reposta”. Portanto, a “percepção” no exemplo em discussão representa os dados que nós possuímos. A “avaliação” representa a análise que vamos fazer utilizando os dados para gerar a “resposta” desejada (aprovar ou reprovar).
Em um processo de concepção de uma RNA, para atuar como a nossa “caixa” de “avaliação”, o primeiro passo é apresentar os dados para a RNA, permitindo que ela busque reproduzir a resposta desejada. Este processo é chamado de treinamento, e é importante que seja feito com apenas um
subgrupo de toda a base de dados. Isso porque na fase de treinamento, a RNA se
especializa em mapear os dados apresentados a ela nas respostas desejadas
(“aprovar” ou “reprovar”), fazendo com que este subgrupo de dados tenha seu
viés mapeado.
[UC1]
Desta forma, a rede já treinada é testada utilizando outro compartimento do conjunto de dados. Nesse teste, será avaliado se a resposta gera resultados coerentes para negociações aprovadas ou recusadas. Caso ela não gere resultados coerentes (e normalmente é o que acontece em um primeiro momento), o formato (ou topologia) da RNA é ajustado (quantidade de neurônios, algoritmo de treinamento, camadas de neurônios) e, assim, o ciclo de treinamento se inicia novamente, como mostra o diagrama abaixo.
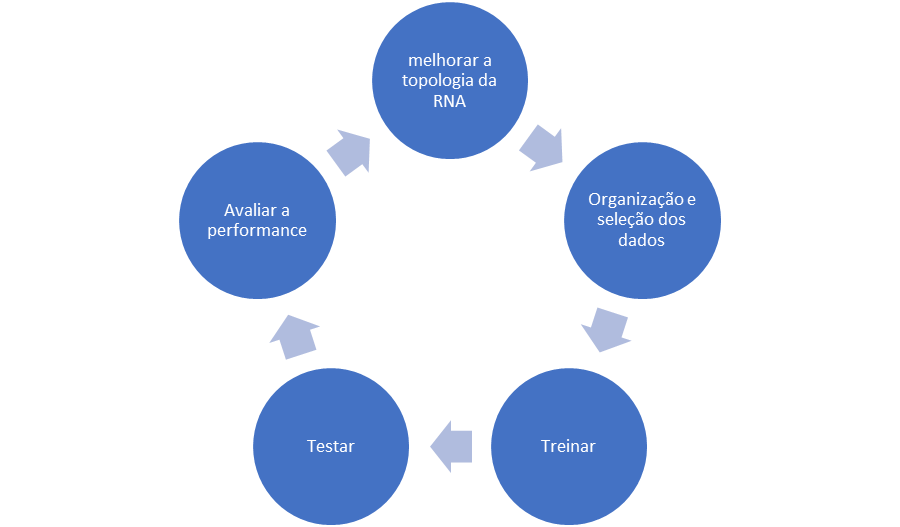
Figura 2: Fluxo de concepção de uma RNA
A organização e seleção dos dados que serão apresentados à RNA é uma fase muito importante e precisa estar muito alinhada com o problema que se pretende resolver. Além disto, como já foi dito, o conjunto de dados precisa ser suficientemente representativo e grande para que possa ser utilizado em blocos diferentes tanto na etapa de treinamento como na de teste. Resumindo, precisamos de vários exemplos de empresas onde conhecemos a priori todo seu comportamento ao longo do período, e seus respectivos graus de riscos e probabilidade de default. Melhor ainda quando temos nessa base de dados as próprias ocorrências efetivas de default.
TREINANDO
Notícias Relacionadas

Opinião da Comunidade
Lubrificante adulterado: ameaça à competitividade da economia brasileira
Por:Carlo Faccio* A adulteração de lubrificantes é uma prática criminosa que representa uma ameaça crescente à saúde da economia brasileira e à integridade do setor de downstream. Seus efeitos são profundos: comprometem a qualidade dos produtos disponíveis no mercado, afetam o desempenho de motores e equipamentos, impõem prejuízos relevantes a cadeias produtivas estratégicas e prejudicam empresas […]

Opinião da Comunidade
Waste-to-Energy e os benefícios socioambientais em comparação com os aterros sanitários
Transformar resíduos não recicláveis em energia é a chave para uma gestão sustentável, segura e eficiente dos resíduos urbanos ao invés de ter como única opção a destinação para aterros sanitários
Para que seja possível entender melhor o que é a etapa de treinamento a Figura 3 mostra uma ilustração deste processo.
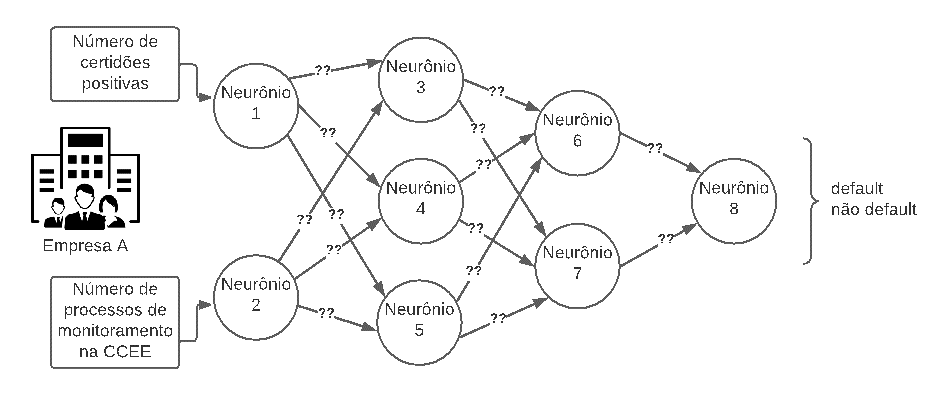
Figura 3: Treinamento ilustrativo de uma RNA
Nesta etapa, os pesos das sinapses dos neurônios (setas com “?? “na Figura 3) devem ser ajustados para uma dada contraparte (“Empresa A” na Figura 3) quando soubermos que por exemplo, a mesma entrou em default. Este processo de ajuste é feito para que, dado um conjunto de dados de entrada (no caso da Figura 3, vemos uma rede com dois dados de entrada), a RNA consiga inferir corretamente se houve default ou não. Tal rotina é repetida para cada empresa que será usada na fase de treinamento (quanto mais empresas, melhor), de tal forma que os pesos sejam ajustados continuamente, gerando gradativamente resultados cada vez mais coerentes para toda a amostra em treinamento.
TESTANDO
Na etapa de testes, a rede neural já treinada na etapa anterior é utilizada com seus pesos fixos para avaliar sua assertividade quanto ao enquadramento correto de outras empresas (que não foram usadas na fase de treinamento).
APROVANDO OU RECALIBRANDO
Caso a performance seja satisfatória na etapa de testes, a Rede Neural treinada é salva e pode ser utilizada para gerar insights sobre a aprovação ou reprovação da contraparte (como ilustra a Figura 4), entrando assim em regime operacional.
Caso a performance não seja satisfatória, os dados devem ser revisitados para avaliar quanto às necessidades de:
- Melhorar a qualidade dos dados utilizados;
- Mudar o formato em que são usados para treinamento, e/ou;
- Alterar a topologia da RNA (como mostra a Figura 2).
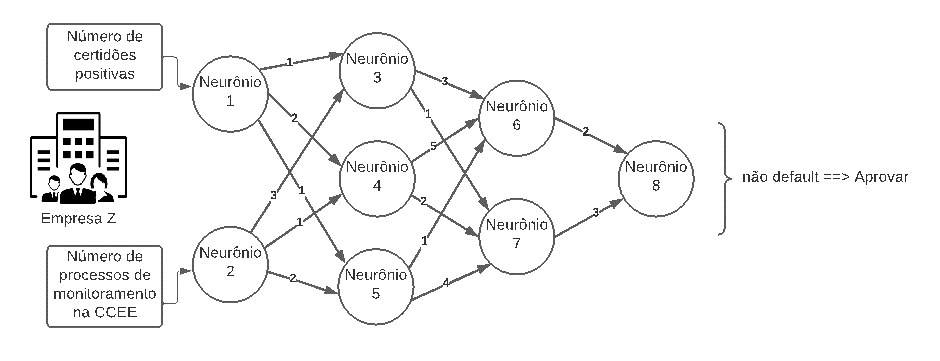
Figura 4: RNA já treinada e aplica à aprovação ou reprovação da contraparte.
Se você chegou até aqui, parabéns!! Mas precisamos esclarecer. Esta é apenas uma pequena amostra sintética e com várias simplificações técnicas (tornando o texto mais didático e acessível). O objetivo foi demonstrar como o uso da IA melhora de forma consistente o processo decisório nas análises de crédito. Ainda que não exista a bala de prata, essa e outras técnicas disponíveis, poderão facilitar demais a sua jornada profissional. E sobretudo, maximizar os resultados de sua empresa.
*Sócios e Fundadores da RISK3
Cada vez mais ligada na Comunidade, a MegaWhat abriu um espaço para que especialistas publiquem artigos de opinião relacionados ao setor de energia. Os textos passarão pela análise do time editorial da plataforma, que definirá sobre a possibilidade e data da publicação.
As opiniões publicadas não refletem necessariamente a opinião da MegaWhat.
Leia mais:
Ricardo Pigatto escreve: Uma verdade inconveniente, versão setor elétrico brasileiro
Leonardo Weiss escreve: Inovação será decisiva para prevenir futuras crises hídricas
")




